
排序算法
排序在我们的生活中很常见啊(((
基础知识
- 排序的稳定性:两个相等元素在排序之后相对位置没有变化(比如A=B,A在B的左边,排完序后A还在B的左边)
- 基本上没有别的了((((
不要说你连什么是时间复杂度和空间复杂度都不知道
冒泡排序
冒泡排序,这是一个效率极低的排序算法,他是通过一个一个数比较大小,然后交换位置使数组有序的算法,因为数字在交换过程中像泡泡,所以叫冒泡排序。
1 | for(int i=1; i<=n; i++){ |
显而易见,这是 $O(n^2)$ 的排序算法
计数排序
相比之下,计数排序是一个比较好的选择(
对于数字比较小的情况下(数字不可以小于零),我们可以统计每个数字的个数,然后按数字输出。
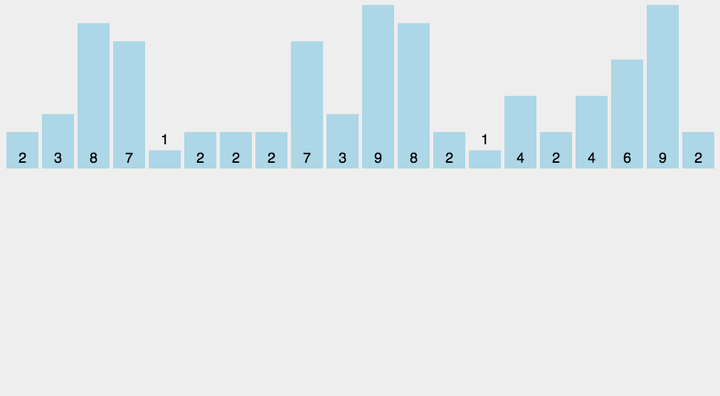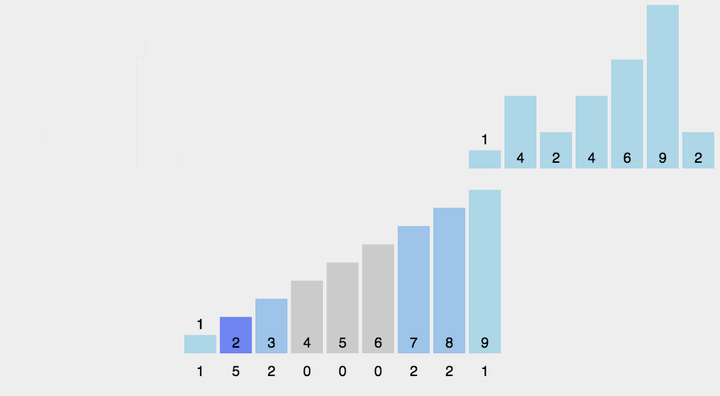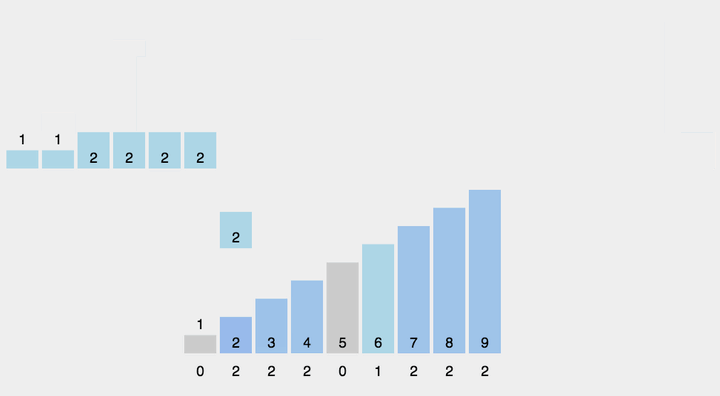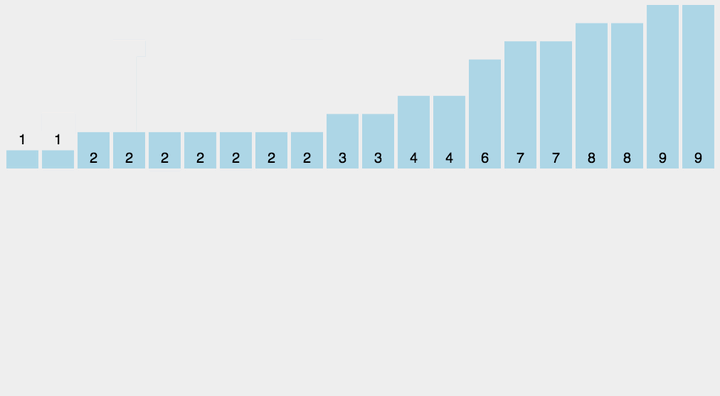
1 | int cnt[110]; |
这是一个 $O(n+k)$ 的排序算法,其实挺棒的
选择排序
选择排序就是对于一个排序,扫一遍,对于第 $i$ 个数字,把他和之后的所有数字中的最小值交换。
1 | for(int i=1; i<=n; i++){ |
这是一个 $O(n^2)$ 的排序算法
插入排序(插排)
插入排序就是一个十分常见的排序方式,比如:

他就是对于这个元素往前找到第一个小于等于他的,然后插入到那个数字后面
1 | for(int i=1; i<n; i++){ |
显而易见,$O(n^2)$ 算法,比较简单
接下来的两个排序相当高端,他们的复杂度都是比前面几个快的多得多的排序
归并排序(归并)
好,首先是第一个,归并排序。
归并归并,何为归并,这其实是一个分治思想,其实也很简单。
把一个数组分开,在分开,最后在递归的时候,使用一定顺序将序列合并成有序的序列,最后完成排序。
1 | void Merge(int l, int r){ |
这是一个 $O(n \log_2 n)$ 的算法
快速排序(快排)
快排其实和归并比起来很不行,他既是不稳定的排序算法,时间复杂度也不稳定,代码还及其难写。
快速排序其实是一个递归和前后指针法:
- 首先选择一个 $\tt keyi$ 位置,一般为序列首。
- 创建两个指针, $\tt prev$ 指向 $\tt keyi$ ,$\tt cur$ 指向 $ \tt prev$$+1$
- $\tt cur$ 往右找小于 $\tt keyi$ 位置的值,如果找到了 $\tt prev$ 往前找大于$ \tt keyi$ 位置的值,然后交换 $\tt cur$ 和 $\tt prev$ 位置的值(注意,这里既然 $\tt cur$找到
arr[cur]>arr[keyi],那么 $\tt cur$ 和 $\tt prev$ 之间的值必然都会大于arr[keyi]) - 最后cur走完序列,再把 $\tt keyi$ 和 $\tt prev$ 位置值交换,这样 $\tt keyi$ 左边都会比他小,右边都会比他大
- 再将区间分为 $\tt [begin,keyi-1],[keyi+1,end]$ 继续递归直至有序
代码我就不附上了(因为不会写

最后,附个小表
| 排序算法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 插入排序 | $O(N^2)$ | $O(N^2)$ | $O(N)$ | $O(1)$ | 稳定 |
| 希尔排序 | $O(N^1.3)$ | $O(N^2)$ | $O(N)$ | $O(1)$ | 不稳定 |
| 选择排序 | $O(N^2)$ | $O(N^2)$ | $O(N^2)$ | $O(1)$ | 不稳定 |
| 堆排序 | $O(N\log_2N)$ | $O(N\log_2N)$ | $O(N\log_2N)$ | $O(1)$ | 不稳定 |
| 冒泡排序 | $O(N^2)$ | $O(N^2)$ | $O(N)$ | $O(1)$ | 稳定 |
| 快速排序 | $O(N\log_2N)$ | $O(N^2)$ | $O(N\log_2N)$ | $O(N\log_2N)$ | 不稳定 |
| 归并排序 | $O(N\log_2N)$ | $O(N\log_2N)$ | $O(N\log_2N)$ | $O(N)$ | 稳定 |
| 计数排序 | $O(N+K)$ | $O(N+K)$ | $O(N+K)$ | $O(N+K)$ | 稳定 |
c++自带sort
在C++中使用 sort 函数需要使用 #include<algorithm> 头文件。
它是一个神奇的函数,在数据较小时使用插入排序,在数据较大时使用快排,在快排递归慢的时候使用堆排序。
在正常使用时,我们只需要传进去需要排序的首尾地址(左闭右开)可以了,比如:
1 | sort(a, a+n); //0~(n-1) |
然后,我们可以自定义排序方式,方法很多,比如:
1 | //在定义结构体时使用 operator |
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.
Comment
